Large Language Models (LLMs) have emerged as promising assistants for
scientific writing. However, there have been concerns regarding the
quality and reliability of the generated text, one of which is citation
accuracy and faithfulness. While most recent work relies on methods
such as LLM-as-a-Judge, the reliability of LLM-as-a-Judge alone is also
in doubt. In this work, we reframe citation evaluation as a problem of
citation attribution alignment, which assesses whether LLM-generated
citations match those a human author would include for the same text. We
propose CiteGuard, a retrieval-aware agent framework designed
to provide more faithful grounding for citation validation.
CiteGuard improves the prior baseline by 10%, and achieves up
to 68.1% accuracy on the CiteME benchmark, approaching human-level
performance (69.2%). It also enables the identification of alternative
but valid citations and demonstrates generalization ability for
cross-domain citation attribution.
Introduction
Scientific writing assistants need to do more than generate fluent text:
they also need to ground claims in the right literature. We study
citation attribution as the task of identifying which paper a human
author would cite for a given excerpt. This framing exposes a core
weakness of naive LLM judging: on CiteME, GPT-4o often rejects correct
citations, with recall as low as 16-17% when it is asked to validate
references directly.
CiteGuard addresses this with retrieval-augmented validation.
Building on CiteAgent, it adds actions that recover missing context,
search within paper text, and validate candidates through stronger
evidence gathering. Across 5-run averages on CiteME,
CiteGuard improves over CiteAgent with the same GPT-4o backend
and reaches 68.1% accuracy with DeepSeek-R1, close to the 69.2% human
reference point.
Method
Precision
Recall
F1
Zero-shot abstract
1.0
0.17
0.29
Few-shot abstract
1.0
0.16
0.27
Zero-shot full text
1.0
0.36
0.53
Few-shot full text
1.0
0.38
0.55
ChatGPT-4o accuracy on citation attribution in the CiteME benchmark.
Contributions.
We introduce CiteGuard, an agent for faithful citation
attribution that retrieves and validates candidate references.
We analyze alternative valid citations with human annotation and use
them to measure agreement beyond the original single-oracle setup.
We extend evaluation to cross-domain and long-paragraph settings
through CiteMulti.
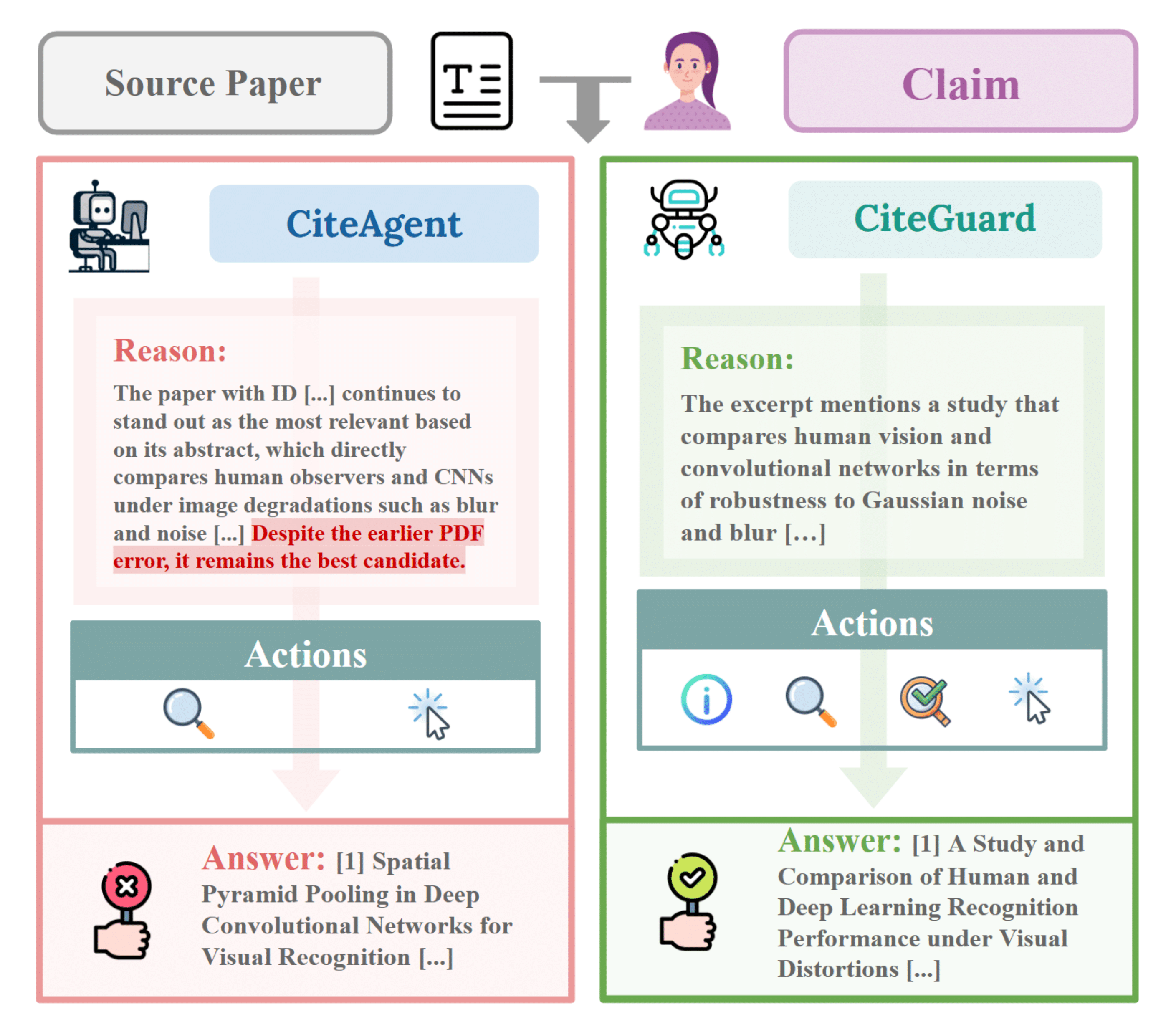
Left: a representative CiteAgent failure case. Right: the CiteGuard
workflow used to recover evidence and rank citations more robustly.
Methodology
CiteGuard extends the CiteAgent action space with retrieval
steps that better handle ambiguous excerpts and incomplete paper access.
The system searches candidate papers, requests more surrounding context
when needed, and validates evidence directly from paper content rather
than depending only on titles, abstracts, or PDF parsing.
The new actions are designed to recover missing context and retrieve
evidence from paper bodies even when PDF access is unreliable.
Results
We evaluate on CiteME,
a benchmark of 130 computer science excerpts with one missing citation
each. The table below reports difficulty-stratified accuracy and 5-run
averages. CiteGuard consistently improves over CiteAgent and
reaches its strongest overall performance with DeepSeek-R1.
Method
Easy (%)
Medium (%)
Med-Hard (%)
Hard (%)
All (%) +/- sigma
CiteAgent + GPT-4o
69.7
52.2
15.4
2.9
35.4 +/- 2.3
CiteGuard + GPT-4o
86.4
65.2
20.5
6.5
45.1 +/- 2.7
CiteGuard + DeepSeek-R1
95.5
87.0
71.8
15.2
68.1 +/- 5.8
CiteGuard + Gemini
81.8
43.5
16.7
0.0
34.2 +/- 2.7
CiteGuard + Kimi-K2
90.9
83.3
41.9
13.0
59.7 +/- 2.1
CiteGuard + Qwen3
81.6
68.8
43.6
10.1
53.1 +/- 3.5
Human
95.5
80.4
69.2
21.7
69.2
CiteME accuracy averaged over 5 runs. DeepSeek-R1 gives the strongest
overall CiteGuard performance at 68.1%, close to 69.2% human
performance.
The paper also reports Bayesian paired comparisons among CiteGuard
variants. DeepSeek-R1 shows strong posterior evidence over GPT-4o,
Gemini, and Qwen3, while its advantage over Kimi-K2 is smaller but
still positive in the reported test.
Comparison vs DeepSeek-R1
Delta Acc (%)
P(Delta > 0)
95% CI
vs GPT-4o
+29.2
1.00
[19.0, 37.8]
vs Gemini
+35.4
1.00
[24.3, 44.2]
vs Qwen3
+31.5
1.00
[21.6, 39.8]
vs Kimi-K2
+19.2
0.99
[9.4, 28.0]
Bayesian paired comparisons reported in the paper for DeepSeek-R1
against other CiteGuard variants.
We also evaluate whether the system can suggest alternative but
still relevant citations. Using aggregated human annotations as a
richer oracle, CiteGuard shows strong agreement with expert judgments,
with inter-annotator agreement of 72.7% in the manual assessment.
Method
Oracle-in-Set@1
Oracle-in-Set@5
Agreement@1
Agreement@5
CiteAgent + GPT-4o
35.4%
49.2%
50.5%
70.1%
CiteGuard + GPT-4o
45.1%
56.7%
62.9%
75.3%
CiteGuard + DeepSeek-R1
68.1%
76.9%
71.6%
82.6%
CiteGuard + Gemini
34.2%
42.4%
48.4%
60.8%
CiteGuard + Kimi-K2
59.7%
70.8%
71.6%
87.8%
CiteGuard + Qwen3
53.1%
69.6%
66.0%
85.8%
Oracle coverage and agreement with human-annotated relevant citations.
CiteGuard not only retrieves the benchmark oracle more often, but also
surfaces high-quality alternatives.
To test generalization, we extend evaluation to CiteMulti, which adds
biomedical, physics and math, and long-paragraph settings. The gains
are smaller than on CiteME, but CiteGuard still improves over CiteAgent
in every reported slice.
Method
BioMed (%)
Long Para. (%)
Phy&Math (%)
All (%)
CiteAgent
26.6
40.0
52.5
39.6
CiteGuard
28.3
46.6
55.0
42.6
CiteMulti accuracy averaged over 3 runs with Kimi-K2.
Analysis
Action Ablation
Both new actions matter. Adding only
ask_for_more_context or only
search_text_snippet already improves substantially over
CiteAgent, and the combination performs best.
Method
Accuracy (%)
CiteAgent
36.2
CiteGuard (+ ask_for_more_context)
53.1
CiteGuard (+ search_text_snippet)
57.7
CiteGuard (+ both)
59.7
Accuracy difference on CiteME when enabling different subsets of the
new CiteGuard actions.
Retrieval vs Long-Context
Replacing find_in_text with full-document
read slightly improves accuracy, but it roughly doubles
token use on average and can require up to 4x more tokens in some
cases. This makes retrieval the more practical default when cost and
latency matter.
Method
Accuracy (%)
Avg. # of Tokens
read
63.1
33,544.68
find_in_text
60.0
15,451.43
Retrieval-based evidence gathering is much cheaper, while
long-context reading provides a modest accuracy gain.
Human-in-the-Loop Tradeoff
The paper also isolates the effect of
ask_for_more_context. The gain is modest on CiteME, but it
matters when the initial excerpt is too short or ambiguous and a user
can provide surrounding context.
Method
Accuracy (%)
CiteGuard (w/o ask_for_more_context)
57.7
CiteGuard (w/ ask_for_more_context)
59.7
Tradeoff of enabling the context-request action in the Kimi-K2
setting.
Iterative Runs
Non-iterative runs are strong, but repeated independent attempts still
help. With CiteGuard + Kimi-K2, accuracy rises from 60.0% with one run
to 75.4% after three iterations.
# of Iterations
Accuracy (%)
1
60.0
2
70.0 (+10.0)
3
75.4 (+5.4)
Accuracy on CiteME for CiteGuard + Kimi-K2 when iterative runs are
enabled.
Reasoning vs Non-Reasoning Models
DeepSeek-R1 and Kimi-K2 differ in style more than in overall behavior.
The reasoning model self-questions more explicitly, while the
non-reasoning model commits earlier, yet both can arrive at human-valid
citations.
Excerpt
A second consideration is how to treat the image itself: the raw
image could be fed directly into the reinforcement learning algorithm
through a series of convolutions [CITATION].
DeepSeek-R1
...But note: the excerpt says "the raw image could be fed directly into the
reinforcement learning algorithm through a series of convolutions". This is
exactly what DQN did. However, let's break it down:
- The citation is likely for the method of using convolutions to process raw
images in RL, not necessarily the entire RL algorithm...
Kimi-K2
...I can still be confident that its abstract already declares it is the first
deep learning model to successfully learn control policies directly from
high-dimensional sensory input, where input is raw pixels...
Comparison to Paper Finders
We also compare against
AI2 Paper Finder.
In this setting, CiteGuard's top-1 DeepSeek-R1 result already exceeds
AI2 Paper Finder's top-10 accuracy, which suggests that excerpt-aware
reasoning helps more than ranking a long generic candidate list.
Method
Top 1
Top 10
AI2 Paper Finder
38.5
60.0
Ours + Gemini
36.9
46.2
Ours + DeepSeek-R1
65.4
84.6
AI2 Paper Finder versus CiteGuard on CiteME.
Alternative Retrieval Pipeline
To test portability, the paper swaps the Semantic Scholar backend for
an arXiv-based retrieval pipeline. Performance drops because arXiv does
not support all of CiteGuard's retrieval actions equally well, but the
framework still remains usable under a constrained backend.
Backend
Easy (%)
Medium (%)
Med-Hard (%)
Hard (%)
All (%)
CiteGuard + Semantic Scholar
95.5
87.0
71.8
15.2
68.1
CiteGuard + arXiv
68.2
54.3
28.2
21.7
43.1
Performance comparison across retrieval backends. Semantic Scholar is
stronger overall, while arXiv demonstrates backend portability.
Cost Analysis
The paper's cost analysis shows that the strongest setting is also
practical to run: DeepSeek-R1 provides the best overall performance at
a much lower per-sample API cost than GPT-4o.
Model
Avg. Input Tokens
Avg. Output Tokens
Avg. Cost / Sample ($)
Platform
GPT-4o
17,931.8
1,705.8
0.12
OpenAI
DeepSeek-R1 (671B / 37B)
15,004.9
1,771.4
0.005
DeepSeek
Gemini-2.0-Flash
19,064.9
1,449.4
0.00
Google (free tier)
Kimi-K2 (1T / 30B)
15,451.4
826.7
0.017
Together AI
Qwen3 (235B / 22B)
14,598.8
936.8
0.003
Together AI
Average token usage and API cost per sample reported in the paper.
Conclusion
CiteGuard reframes citation evaluation as grounded attribution
and shows that retrieval-aware validation is much more reliable than
asking an LLM to judge citations in isolation. On CiteME, it closes the
gap to human performance, surfaces high-quality alternative citations,
and shows promising transfer to cross-domain and long-paragraph
settings.
BibTeX
@misc{choi2025citeguardfaithfulcitationattribution,
title={CiteGuard: Faithful Citation Attribution for LLMs via Retrieval-Augmented Validation},
author={Yee Man Choi and Xuehang Guo and Yi R. Fung and Qingyun Wang},
year={2025},
eprint={2510.17853},
archivePrefix={arXiv},
primaryClass={cs.DL},
url={https://arxiv.org/abs/2510.17853}
}
Acknowledgement
We sincerely thank our annotators for their annotations.